
Как надо и как не надо использовать ABAP CDS View
Начиная с версии 7.4 в ABAP появилась технология Core Data Services - расширенная OpenSQL нотация описания моделей данных с широкими возможностями обработки данных, приправленная аннотациями, позволяющими встраивать в CDS информацию, используемую различными фреймворками. Технология активно развивается и продвигается SAP - появившись в 7.4 только для серверов SAP HANA, в 7.5 ее поддержка была расширена и на остальные поддерживаемые сервера, а также получила много полезных дополнений, как, например, генерацию BOPF объектов на основе аннотаций.
При этом CDS является достаточно мощным механизмом, позволяющим опустить многие вычисления и выборки данных в трехуровневой архитектуре SAP с уровня приложений на уровень БД (подход, называемый “code push-down”). Вместе с использованием SAP HANA, которая умеет быстро обрабатывать такие запросы, эта технология предоставляет разработчику достаточно мощный инструмент по описанию моделей данных, которые можно затем удобно использовать в ABAP.
Однако с большой силой приходит и большая ответственность, о которой мы сегодня и поговорим. Но сперва в двух словах о том, что же такое ABAP CDS View.
##Описание моделей с использованием ABAP CDS View
Как уже было сказано, CDS View предназначены для описания моделей данных, которые могут быть значительно расширены с использованием аннотаций. Технически CDS View похож на обычный Dictionary View - это выборка из одной или нескольких таблиц, где над выбираемыми данными могут быть выполнены различные операции SQL. Типичная модель данных, получаемых в итоге - иерархическая структура из различных CDS View, собирающих данные по системе и так или иначе преобразующих их, предоставляя пользователю готовый набор данных в виде таблицы, которые можно получить через обычный SELECT. При этом для каждой CDS View при активации будет генерироваться select, который и будет выполняться при запросе.
Вот пример простого CDS View и сгенерированного для него запроса:
define view I_MRPSalesOrder
as select from I_SalesOrderScheduleLine
association [0..1] to I_CustomerMaterial as _CustomerMaterialInfoRecord on $projection.salesorganization = _CustomerMaterialInfoRecord.SalesOrganization
and $projection.distributionchannel = _CustomerMaterialInfoRecord.DistributionChannel
and $projection.customer = _CustomerMaterialInfoRecord.Customer
and $projection.material = _CustomerMaterialInfoRecord.Material
association [0..1] to I_WBSElement as _WBSElement on $projection.WBSElementInternalID = _WBSElement.WBSElementInternalID
{
key SalesOrder,
key SalesOrderItem,
key ScheduleLine,
_SalesOrder.SalesOrderType,
_SalesOrder.SalesOrderDate, //DocumentDate,
_SalesOrderItem.ProductionPlant as MRPPlant,
_SalesOrderItem.Material,
_SalesOrderItem._Material._Text[1: Language = $session.system_language ].MaterialName,
_SalesOrderItem.WBSElement as WBSElementInternalID,
_SalesOrder._SoldToParty.Customer,
_SalesOrder._SoldToParty.CustomerName,
_SalesOrder._SoldToParty.CustomerFullName,
_SalesOrder._SoldToParty._StandardAddress.PhoneNumber,
_SalesOrder._SoldToParty._StandardAddress._DefaultEmailAddress.EmailAddress,
_SalesOrderItem.MaterialByCustomer,
BaseUnit, //MaterialBaseUnit
_SalesOrderItem.DeliveryDateQuantityIsFixed, // DeliveryDateQuantityIsFixed
_SalesOrder.SalesOrganization,
_SalesOrder.DistributionChannel,
_SalesOrderItem.Division,
_SalesOrder.DeliveryBlockReason,
_SalesOrder._DeliveryBlockReason._Text[1: Language = $session.system_language ].DeliveryBlockReasonText,
case _SalesOrder.DeliveryBlockReason
when '' then ''
else 'X'
end as DeliveryIsBlocked,
RequestedDeliveryDate,
ProductAvailabilityDate,
ScheduleLineOrderQuantity as OrderQuantity,
ConfdOrderQtyByMatlAvailCheck as ConfirmedQuantity,
(ScheduleLineOrderQuantity - ConfdOrderQtyByMatlAvailCheck) as OpenQuantity,
OrderQuantityUnit as SalesUnit,
ConfdOrderQtyByMatlAvailCheck as ConfirmationTotalQuantity,
DeliveredQtyInOrderQtyUnit,
DeliveredQuantityInBaseUnit,
OpenConfdDelivQtyInBaseUnit,
OpenConfdDelivQtyInOrdQtyUnit,
_WBSElement,
_CustomerMaterialInfoRecord,
_SalesOrder,
_SalesOrderItem
}
Стандартный CDS View I_MRPSalesOrder
CREATE VIEW "IMRPSALESORDER" AS SELECT
"ISDSLSORDSCHEDLN"."MANDT" AS "MANDT",
"ISDSLSORDSCHEDLN"."SALESORDER",
"ISDSLSORDSCHEDLN"."SALESORDERITEM",
"ISDSLSORDSCHEDLN"."SCHEDULELINE",
"=A0"."SALESORDERTYPE",
"=A0"."SALESORDERDATE",
"=A1"."PRODUCTIONPLANT" AS "MRPPLANT",
"=A1"."MATERIAL",
"=A3"."MATERIALNAME",
"=A1"."WBSELEMENT" AS "WBSELEMENTINTERNALID",
"=A4"."CUSTOMER",
"=A4"."CUSTOMERNAME",
"=A4"."CUSTOMERFULLNAME",
"=A5"."PHONENUMBER",
"=A6"."EMAILADDRESS",
"=A1"."MATERIALBYCUSTOMER",
"ISDSLSORDSCHEDLN"."BASEUNIT",
"=A1"."DELIVERYDATEQUANTITYISFIXED",
"=A0"."SALESORGANIZATION",
"=A0"."DISTRIBUTIONCHANNEL",
"=A1"."DIVISION",
"=A0"."DELIVERYBLOCKREASON",
"=A8"."DELIVERYBLOCKREASONTEXT",
CASE "=A0"."DELIVERYBLOCKREASON" WHEN N'' THEN N'' ELSE N'X'
END AS "DELIVERYISBLOCKED",
"ISDSLSORDSCHEDLN"."REQUESTEDDELIVERYDATE",
"ISDSLSORDSCHEDLN"."PRODUCTAVAILABILITYDATE",
"ISDSLSORDSCHEDLN"."SCHEDULELINEORDERQUANTITY" AS "ORDERQUANTITY",
"ISDSLSORDSCHEDLN"."CONFDORDERQTYBYMATLAVAILCHECK" AS "CONFIRMEDQUANTITY",
CAST(
(
"ISDSLSORDSCHEDLN"."SCHEDULELINEORDERQUANTITY" - "ISDSLSORDSCHEDLN"."CONFDORDERQTYBYMATLAVAILCHECK"
) AS DECIMAL(000014,000003)
) OPENQUANTITY,
"ISDSLSORDSCHEDLN"."ORDERQUANTITYUNIT" AS "SALESUNIT",
"ISDSLSORDSCHEDLN"."CONFDORDERQTYBYMATLAVAILCHECK" AS "CONFIRMATIONTOTALQUANTITY",
"ISDSLSORDSCHEDLN"."DELIVEREDQTYINORDERQTYUNIT",
"ISDSLSORDSCHEDLN"."DELIVEREDQUANTITYINBASEUNIT",
"ISDSLSORDSCHEDLN"."OPENCONFDDELIVQTYINBASEUNIT",
"ISDSLSORDSCHEDLN"."OPENCONFDDELIVQTYINORDQTYUNIT"
FROM (
(
(
(
(
(
(
(
"ISDSLSORDSCHEDLN" "ISDSLSORDSCHEDLN" LEFT OUTER MANY TO ONE JOIN "ISDSALESORDER" "=A0" ON (
"ISDSLSORDSCHEDLN"."MANDT" = "=A0"."MANDT" AND
"ISDSLSORDSCHEDLN"."SALESORDER" = "=A0"."SALESORDER"
)
) LEFT OUTER MANY TO ONE JOIN "ISDSLSORDERITEM" "=A1" ON (
"ISDSLSORDSCHEDLN"."SALESORDERITEM" = "=A1"."SALESORDERITEM" AND
"ISDSLSORDSCHEDLN"."SALESORDER" = "=A1"."SALESORDER" AND
"ISDSLSORDSCHEDLN"."MANDT" = "=A1"."MANDT"
)
) LEFT OUTER MANY TO ONE JOIN "IMATERIAL" "=A2" ON (
"ISDSLSORDSCHEDLN"."MANDT" = "=A2"."MANDT" AND
"=A1"."MATERIAL" = "=A2"."MATERIAL"
)
) LEFT OUTER MANY TO ONE JOIN "IMATERIALTEXT" "=A3" ON (
"=A2"."MATERIAL" = "=A3"."MATERIAL" AND
"=A3"."LANGUAGE" = SESSION_CONTEXT(
'LOCALE_SAP'
) AND
"ISDSLSORDSCHEDLN"."MANDT" = "=A3"."MANDT"
)
) LEFT OUTER MANY TO ONE JOIN "I_CUSTOMER_CDS" "=A4" ON (
"ISDSLSORDSCHEDLN"."MANDT" = "=A4"."MANDT" AND
"=A0"."SOLDTOPARTY" = "=A4"."CUSTOMER"
)
) LEFT OUTER MANY TO ONE JOIN "IADDRESS" "=A5" ON (
"ISDSLSORDSCHEDLN"."MANDT" = "=A5"."MANDT" AND
"=A4"."ADDRESSID" = "=A5"."ADDRESSID"
)
) LEFT OUTER MANY TO ONE JOIN "IADDREMAILADDR" "=A6" ON (
"=A6"."ADDRESSID" = "=A5"."ADDRESSID" AND
(
"=A6"."PERSON" = "=A5"."PERSON" OR "=A6"."PERSON" = N''
) AND
"=A6"."ISDEFAULTEMAILADDRESS" = N'X' AND
"ISDSLSORDSCHEDLN"."MANDT" = "=A6"."MANDT"
)
) LEFT OUTER MANY TO ONE JOIN "ILEDELIVBLKRSN" "=A7" ON (
"ISDSLSORDSCHEDLN"."MANDT" = "=A7"."MANDT" AND
"=A0"."DELIVERYBLOCKREASON" = "=A7"."DELIVERYBLOCKREASON"
)
) LEFT OUTER MANY TO ONE JOIN "ILEDELIVBLKRSNT" "=A8" ON (
"=A7"."DELIVERYBLOCKREASON" = "=A8"."DELIVERYBLOCKREASON" AND
"=A8"."LANGUAGE" = SESSION_CONTEXT(
'LOCALE_SAP'
) AND
"ISDSLSORDSCHEDLN"."MANDT" = "=A8"."MANDT"
)
Сгенерированный для него SQL запрос
А вот иерархическая структура, показывающая последовательность выборки данных по дереву CDS вплоть до реальных таблиц БД:
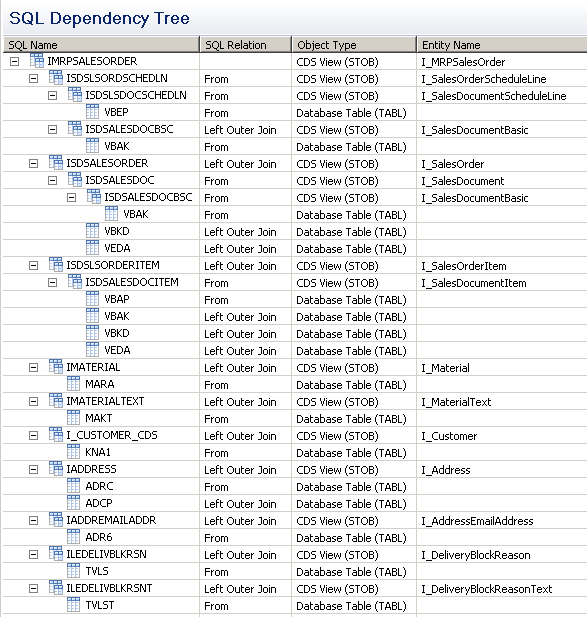
Сам инструмент достаточно удобен, если речь идет именно о выборке данных, и позволят качественно отделить модель от бизнес-логики при разработке приложения. При этом многие новые технологии SAP построены именно на CDS View, например новый подход к моделированию приложений для Fiori, полностью основанной на BOPF и CDS, которая уже применяется в новых модулях для S/4, например в EHS.
Однако благодаря широким возможностям CDS View по обработке данных (а возможность применения AMDP делает их практически безграничными) появляется возможность использования технологии для решения крайне широкого спектра задач. Однако не для всего они хорошо подходят, и неправильное применение этого инструмента превращает разработку и поддержку в настоящее мучение. В этой заметке я рассмотрю основные случаи, когда стоит и не стоит использовать CDS View и некоторые особенности текущего состояния этой технологии, которые стоит знать перед тем, как начинать серьезное использование ее в проекте.
##Когда стоит использовать CDS View
###При описании моделей данных
Как следует из документации, технология была разработана для описания моделей данных, используемых в ABAP. Например, работая в SD с заказом на поставку, можно написать набор CDS View, которые будут выбирать всю необходимую информацию по заказу (при этом информация для различных статусов заказа может считываться из различных таблиц при необходимости), и формировать на ее основе единую структуру заказа со всеми необходимыми полями в виде одной готовой таблицы (или нескольких связанных таблиц, если имеют место какие-то множественные данные), которую можно просто считать в ABAP и сразу же использовать для какой-то бизнес логики, без каких-то дополнительных преобразований и считываний дополнительных данных из БД.
Концепция CDS предполагает, что все выборки, расчеты и преобразования данных, релевантных для модели, будут происходить “не выходя” из БД, а на сервер приложений будут переданы только необходимые данные и ничего лишнего. Это полностью противоречит существовавшему раньше подходу к работе с БД в SAP, в рамках которого предполагалось минимально нагружать базу, а все расчеты выполнять на сервере приложений.
Это все позволяет один раз описать модель данных с указанием всех связей между таблицами, логикой поиска и выборки данных, каких-то преобразований и агрегаций, и потом только обращаться к ней за данными, не вдаваясь в особенности реализации, и не повторяя раз за разом один и тот же код по выборке и анализу данных соответствующей сущности.
##Когда не стоит использовать CDS View
###Реализация бизнес-логики в модели
То, для чего однозначно не стоит использовать эту технологию - реализация любой бизнес-логики на уровне БД. Помимо идеологических соображений этому есть несколько веских причин:
- смешивание уровней логики и модели - про то, почему это плохо, грамотно и очень подробно расписано в любой книге про архитектуру приложений, поэтому я не буду подробно вдаваться в объяснения. Вкратце - модель данных и бизнес-логика изменяются независимо друг от друга, с разной частотой и в зависимости от разных факторов, поэтому они должны быть максимально независимы друг от друга;
- возможности синтаксиса - CDS View как подмножество SQL ориентирован именно на построение запросов к БД для получения данных и сопутствующие операции - агрегации, аналитика, приведения типов, простые преобразования. При этом он не подходит для реализации сложных условий или форматирования строк. Использовать какие-то текстовые константы также плохая идея, так как они не подлежат переводу и крайне затрудняют поиск и поддержку текстов в системе;
- частые изменения в бизнес-логике - одной из характерных особенностей бизнес-логики является высокая частота изменений, которые к тому же тяжело предсказать и детерминировать. Иерархическая структура моделей данных, основанных на CDS, делает изменения в логике их работы крайне трудоемкими и болезненными. Так как основной механизм, исполняемый CDS View, это построение таблиц данных, реализация бизнес-логики на этом уровне требует большого количества костылей и сложных решений, которые значительно снижают отказоустойчивость и уменьшают производительность, а изменения логики в одном месте часто приводят к формированию некорректных выборок в другом;
- сложность тестирования - так как CDS View является самостоятельным программным модулем, который содержит логику, она должна быть покрыта тестами наравне с другими частями системы. В версии 7.4 данные, возвращаемые CDS View, можно заменить заглушкой, а с версии 7.5 SAP предоставляет возможность полноценного юнит-тестирования отдельных CDS View либо иерархии нескольких из них вместе. При этом синтаксис такого теста получается достаточно сложным (благо вместе с ADT поставляется визард для генерации юнит-тестов для выбранного CDS View), а изменение интерфейса тестируемого объекта и проверочных значений достаточно трудоемким. Это удовлетворительно подходит для тестирования моделей, описанных через CDS View (правда ни о каком TDD здесь я бы говорить не стал), но при актуализации тестов после каждого изменения бизнес-логики, находящейся в модели, вам придется затратить поистине огромное время, не получив при этом ни капли удовольствия.
###Формирование слишком сложных моделей
Модель данных как, впрочем, и любая другая сущность не должна быть чересчур сложной и комплексной. Если вы видите, что модель получилась слишком большой, тянет данные из кучи мало связанных таблиц и имеет сложную логику, стоит остановиться и постараться разбить все это на несколько более связных моделей, которыми потом можно будет удобно оперировать в ABAP.
К тому же в БД (в частности HANA) есть ограничение по глубине селекта, и запросы начинают бодро падать в дамп на особенно крупных моделях данных. Не знаю, достиг ли я дна, или это распространенная ситуация, но нужно держать это в голове при разработке особенно всеобъемлющих CDS View.
###Формирование моделей с большим количеством условий
Как в предыдущем пункте, речь здесь идет о сложности модели, но теперь с точки зрения логики. CDS View не поддерживают каких-либо списков значений, а добавить данные из таблицы БД в качестве списка достаточно накладно, поэтому такие вещи, которые в ABAP решались при помощи RANGE, в CDS View приходится реализовывать вручную. Иногда в результате получаются достаточно монструозные конструкции, в процессе написания которых клавиши Ctrl и C изрядно нагреваются. Поддерживать такое достаточно трудоемко, особенно когда подобные условия приходится накладывать на несколько CDS одновременно. Если есть возможность реализовать подобные ограничения силами ABAP, в большинстве случаев лучше так и сделать.
###Реализация логики, не относящейся к моделированию данных
Еще одной крайностью является запихивание в CDS View всей логики приложения по выбору данных, а не только модели. К сожалению, новая модель разработки под Fiori явно подталкивает разработчиков к этому при использовании аннотаций для генерации OData-сервисов из CDS. Собственно, проблемы те же, что и в случае с бизнес-логикой - отличие инструментария, имеющегося в CDS для построения запросов от того, что нужно для реализации остальной программной логики. Из-за этого CDS View становятся сложными и трудно поддерживаемыми, а также наполняются крайне неоднозначными решениями.
К этому относится все, что не касается напрямую модели, но не является непосредственной реализацией бизнес-логики - форматирование строк, построение печатных отчетов, всевозможный анализ данных (не аналитика, а именно анализ значений, например парсинг строк или проверки на основе регулярок), выборка технических данных, не относящихся к модели и т.п. Это не всегда очевидно, но нужно стараться держать модель “чистой” от инородной логики и данных, чтобы ее было удобно тестировать и поддерживать, а также чтобы соблюдать разделение ответственностей.
##Особенности работы с CDS View
При работе с CDS в любом случае нужно иметь в виду определенные особенности, которые могут вылиться в длительную незапланированную работу или сложную поддержку, если на них не обратить внимание заранее.
Как уже было сказано, CDS View достаточно утомительно покрывать тестами. Несмотря на то, что ADT позволяет сгенерировать необходимый boilerplate код, при минимальных изменениях все это придется редактировать вручную. А практика показывает, что минимальные изменения в логике построения модели зачастую приводят к кардинальным изменениям в составляющих модель View. Просто обратите внимание на то, что изменения в таких юнит-тестах потребуют от вас много усилий, и либо пишите тесты в самом конце разработки, либо дробите модели на какие-то более атомарные части, которые будут изменяться с меньшей вероятностью, и покрывайте тестами их.
Другая особенность - “уязвимость” к изменениям логики построения модели, когда незначительные правки, вроде изменения кардинальности каких-то компонентов с 1:1 на 1:N, или добавление значения из какой-то другой таблицы, которое оказывается string (LOB) и срезает добрую половину функционала CDS из-за ограничений по работе с LOB, или добавляется какая-то простая с точки зрения процесса связь, которая технически тянет за собой дюжину таблиц, необходимых, чтобы эту связь построить. Сюда же можно добавить проблемы, вызванные иерархической структурой моделей, основанных на CDS. Небольшие изменения на нижних уровнях могут поломать результирующую модель, да так неявно, что концов не сыскать.
Ну и еще одной не столь значительной для разработки, но крайне неприятной для поддержки является невозможность хоть как-то обрабатывать ошибки (а именно неконсистентности данных), возникающих при работе CDS. Чем больше логических условий реализовано (case, outer join, ассоциации, по которым может не найтись данных или найтись больше, чем надо, парсинг строк и т.п.), тем больше вероятность, что что-то будет работать не так, как запланировано, даже если на этапе разработки утверждалось, что такого случиться не может (об этом я писал в другой статье). В этом случае не получится, как в ABAP, проверить правильность заполнения данных, проверить валидность значений, проверить нашлось ли на каком-то шаге то, что искали, или нет - CDS View просто либо вернет данные, либо нет, третьего не дано. Из этого вытекает следующая проблема - пользователи (или тестировщики) начинают жаловаться, что программа не работает, после часов дебага выясняется, что какой-то параметр где-то заполнен не так, как предполагалось при постановке задачи, параметр исправляется, работа продолжается. Но осадочек-то остается!
И в этом случае нельзя сделать простейшую проверку и вывести сообщение о том, что “таких-то данных не хватает” или “такой-то параметр заполнен неверно”. Все, чем располагает разработчик - сформированная модель, и можно только догадываться по косвенным признакам, что что-то пошло не так на том или ином шаге. Поэтому при возможности все такие вещи, как логические ветвления и принятия решений, стоит вынести на сторону ABAP, чтобы была полноценная возможность грамотно обработать ошибки.
##Что получаем в итоге
В результате можно сделать следующий вывод - CDS View - отличная технология, позволяющая вынести в отдельные модули описание моделей при разработке (тем самым уменьшив связанность программы) и значительно оптимизировать их производительность, опустив много расчетов и преобразований на уровень быстрой in-memory HANA DB, разгрузив тем самым узкий канал между БД и сервером приложений. Модели, реализованные в CDS, подлежат покрытию тестами (хоть и не совсем простому), а также имеют довольно мощный функционал по сравнению с обычным OpenSQL, применяющимся в ABAP. А семантика аннотаций позволяет генерировать на основе CDS View множество сущностей SAP практически на лету - OData сервисы, бизнес-объекты, страницы приложений Fiori, инфокубы и другое. Технология активно развивается и точно не будет забыта SAP в ближайшие годы, тем более что все свежие разработки в S/4 базируются именно на ней.
С другой стороны не стоит забывать, что технология предназначена именно для описания моделей, поэтому она крайне негативно отзывается на включение в них чужеродной логики, что приводит к болезненной и истощающей поддержке такого кода.
Используйте технологию с умом, ведь день ото дня она будет становиться только более распространенной в продуктах SAP.
comments