
Иерархия виртуальной модели данных CDS View
В настоящее время все большее распространение получают системы на основе S/4, одной из ключевых особенностей которых является основанная на CDS View виртуальная модель данных, на которой построена концепция “Code Push Down”.
Концепция виртуальных моделей заключается в том, что поверх таблиц БД строится древовидная иерархия CDS View, описывающих модели данных различного свойства с различными назначениями. В этой заметке я скажу пару слов про то, какие виды CDS View бывают в иерархии, и как правильно такие иерархии строить.
Виртуальная модель данных
Ключевой фичей S/4HANA систем является концепция “Code Push Down” - перенос вычисления модели данных с сервера приложений на сервер базы данных, а именно SAP HANA. При этом все построение модели, включающее расчеты, агрегации и фильтрации, происходят внутри БД, и через интерфейс БД на сервер приложений передается только тот набор данных, который требуется исполняемому приложению. Это противоположно подходу, реализованного в R3 системах, когда данные выбирались из базы данных максимально оптимальным способом и затем уже обрабатывались и фильтровались на сервере приложений (в ABAP коде).
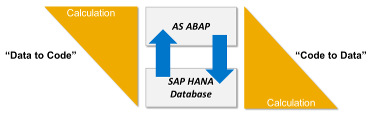
Картинка принадлежит SAP AG
Это достигается (по словам SAP) за счет того, что in-memory СУБД HANA позволяет произвести такие операции очень быстро (по сравнению с классическими РСУБД) и тем самым разгружает канал соединения между сервером приложений и сервером БД, и экономит время на обработку данных программой.
Основой для моделирования на HANA является виртуальная модель данных (Virtual Data Model - VDM), состоящая из набора CDS View различного характера.
CDS View логически разделяются на три уровня:
- basic,
- composite,
- consumption.
Каждый из этих уровней определяется аннотацией @VDM.viewType: #<...> и соответственно BASIC/COMPOSITE/CONSUMPTION. В справке написано, что эта аннотация используется для внутреннего саповского структурирования и интерпретации CDS View, однако никакого реального эффекта от этих аннотаций не замечено, и явной информации о том, для чего конкретно они нужны, у меня нет. Если вы что-то по этому поводу знаете, поделитесь в комментариях.
Итак, рассмотрим подробнее каждый уровень VDM и примеры использования.
Basic View
В целях совместимости данные в S/4 в большинстве своем хранятся в тех же таблицах, что и в R3 (особенно старые продукты вроде ERP, так как новые вроде EHS реализованы сразу на BOPF). Кто работал со стандартными таблицами, знает, насколько они запутаны и насколько непрозрачно называются сами таблицы и их поля (к тому же большинство являются сокращениями от немецких названий).
Однако одной из целей переработки S/4 систем было упрощение транзакций и моделей данных. Поэтому поверх стандартных таблиц реализовываются Basic CDS View, которые имеют нормальные читабельные названия полей и самого ракурса вместо технических имен полей в таблице. Эти CDS View являются интерфейсом доступа к данным таблиц БД (и table functions), и прямое обращение к таблицам теперь считается плохой практикой.
В качестве примера можно посмотреть CDS View I_Material, реализующий интерфейсный доступ к данным таблицы мастерданных материалов MARA.
Предполагается, что для каждой таблицы будет создана только одна Basic View, описывающая эту конкретную атомарную сущность. Эта View должна быть максимально универсальной с целью ее переиспользования, то есть в ней не должно быть никаких не специфичных для нижележащей сущности данных - не должно быть агрегаций, изменений или конвертаций данных, параметров или WHERE-условий.
Basic View обычно считывают данные с одной таблицы БД, либо, если поля сущности распределены по нескольким таблицам, то допустимо делать JOIN с ними (хороший пример - CDS View I_SalesDocumentItem). Однако, чтобы описать связь с другими сущностями (другими таблицами), необходимо добавлять ассоциации на лежащие над ними Basic View, а не на сами таблицы.
Basic View должны иметь ассоциации только на другие Basic View. Эти ракурсы составляют нижний уровень иерархии VDM.
Для именования Basic CDS View принят нейминг I_*, или Z*_I_* соответственно.
Для определения ракурса используется аннотация @VDM.viewType: #BASIC.
По большому счету для каждой таблицы, которую вы создаете, должна создаваться Basic CDS View поверх нее, в которой будут описаны нормальные названия полей, их семантика, текстовые ассоциации и ассоциации к другим сущностям (также Basic CDS View ).
Composite View
Следующий уровень иерархии составляют Composite View - ракурсы, описывающие специфичные для определенного приложения или логики. Они описывают уже конкретную модель данных, со специфичной для нее логикой, фильтрацией, агрегацией, параметрами и т.п. Composite View получают данные из Basic View, или же из других композитных ракурсов. То же и с ассоциациями. Таким образом эти ракурсы комбинируют данные из базовых атомарных сущностей в конкретную модель, специфичную для одного или нескольких приложений.
По своей природе Composite View избыточны, то есть одни и те же базовые сущности могут встречаться в различных композитных ракурсах, например для агрегаций, аналитики, каких-то расчетов и конвертаций, просто выборки данных и так далее. Да и просто для различных приложений, где структура данных модели различна.
Однако они, как и базовые ракурсы, также могут быть переиспользованы, если построенная модель имеет универсальный характер - например CDS, рассчитывающая годовой оборот предприятия, может быть использована во множестве отчетов.
Для именования Composite View также принят нейминг I_*, или Z*_I_* соответственно.
Для определения ракурса используется аннотация @VDM.viewType: #COMPOSITE.
В целом Composite View представляет собой выборку данных из одной или множества базовых таблиц, скомпонованную и преобразованную таким образом, чтобы служить в качестве готовой модели данных для определенного приложения или вышестоящих CDS View.
Consumption View
Последний, верхний уровень иерархии - Consumption CDS View. Они описывают непосредственно взаимодействие приложения с нижележащей иерархией CDS, и создаются отдельно для каждого приложения. Они не являются универсальными, и не предполагают переиспользования (хотя, конечно, вам никто не мешает).
В Consumption View описываются специфические для приложения параметры - внешний вид полей Fiori приложения, средства поиска и другие характеристики относительно того, в каком виде данные будут потребляться приложением.
Для именования Consumption View принят следующий нейминг:
- CDS для использования в приложениях имеют префикс C_*, или Z*_C_* соответственно;
- CDS для использования во внешних API имеют префикс A_*, или Z*_A_* соответственно
Для определения ракурса используется аннотация @VDM.viewType: #CONSUMPTION.
В итоге на этом уровне мы описываем то, как данная модель будет выглядеть в рамках использующего ее приложения.
Построение иерархии CDS View
Для большинства стандартных таблиц CDS View уже существуют, поэтому рассмотрим пример с Z-таблицами.
Допустим у вас есть таблицы, описывающие список магазинов и набор доступного товара на каждом из них, а также история продаж.
- ztest_shop - список магазинов;
- ztest_shop_t - соответствующая текстовая таблица;
- ztest_shop_prod - список товаров, находящихся в каждом магазине;
- ztest_shop_hist - история продаж магазина.
Уровень базовых моделей
Сначала создаем для каждой таблицы Basic CDS View, в которых даем читаемые названия полям таблицы (принято использовать CamelCase, хотя по факту CDS View регистронезависимы). Описываем ассоциации другим Basic CDS View, например на заголовок и позиции документа соответственно, а также на CDS View для соответствующих тестовых таблиц.
Четырем таблицам БД соответствуют четыре Basic CDS View:
- Ztest_I_Shop
- Ztest_I_ShopText
- Ztest_I_ShopProducts
- Ztest_I_ShopSalesHistory
Пример:
@AbapCatalog.sqlViewName: 'ZTEST_VSHOP'
@AbapCatalog.compiler.compareFilter: true
@AccessControl.authorizationCheck: #CHECK
@VDM.viewType: #BASIC
@EndUserText.label: 'Shop Info'
define view Ztest_I_Shop
as select from ztest_shop
association [*] to Ztest_I_ShopText as _Text on _Text.ShopID = $projection.ShopID
association [*] to Ztest_I_ShopProducts as _Products on _Products.ShopID = $projection.ShopID
association [*] to Ztest_I_ShopSalesHistory as _SalesHistory on _SalesHistory.ShopID = $projection.ShopID
{
@ObjectModel.text.association: '_Text'
@ObjectModel.foreignKey.association:[ '_Products', '_SalesHistory']
key shop_id as ShopID,
@Semantics.address.label: true
address as Address,
_Text,
_Products,
_SalesHistory
}
Эти CDS View описывают интерфейс доступа к данным соответствующих таблиц, и в дальнейшем будут они использоваться, когда различные приложения будут обращаться к данным и структуре этих таблиц в своих моделях.
Уровень моделей приложений
Далее переходим на уровень композитных ракурсов, на котором описаны специфичные для приложений модели. Допустим, что у нас есть приложение, которое будет показывать общее количество товара по всем магазинам и рассчитывать примерный срок пополнения запаса товара в каждом в зависимости от истории продаж.
На этом уровне реализуются различные операции, выполняемые над данными таблиц. А именно, агрегации, арифметические операции, конвертации валют, единиц измерения или дат, фильтрация данных и так далее. Само собой, в зависимости от сложности моделируемой логики, модель может состоять из множества CDS View, последовательно преобразующих данные. На практике такое часто случается, поэтому необходимо следить за сложностью иерархии и количеством таблиц, участвующих в построении модели.
В примере логика достаточно простая и модель приложения можно реализовать в несколько ракурсов.
Расчет даты, до которой необходимо пополнить запас товара в магазине:
@AbapCatalog.sqlViewName: 'ZTEST_VPRODREPL'
@AbapCatalog.compiler.compareFilter: true
@AccessControl.authorizationCheck: #CHECK
@VDM.viewType: #COMPOSITE
@EndUserText.label: 'Replenishment of each product'
define view Ztest_I_ProductReplenishment
with parameters
p_horizon_days : abap.int4,
p_current_date : abap.dats
as select from Ztest_I_ShopProducts as Stock
left outer join Ztest_I_ProductHorizonSum(
p_horizon_days: $parameters.p_horizon_days
) as History on History.Material = Stock.Material
and History.ShopID = Stock.ShopID
{
key Stock.Material,
key Stock.ShopID,
@Semantics.businessDate.to: true
cast(case
when History.Amount is not null and History.Amount <> 0
then dats_add_days(
$parameters.p_current_date,
ceil(division(Stock.AvailableAmount, History.Amount , 3) * $parameters.p_horizon_days),
'FAIL')
else '99991231'
end as abap.dats) as ReplenishmentDate,
_Shop,
_Material
}
Полный текст Composite CDS View
Уровень отображений и интерфейсов
В последнюю очередь необходимо адаптировать эти модели данных для отображения. В случае smart templates это могут быть аннотации, описывающие отображение полей, в случае IDA это могут быть названия столбцов, также сюда относится OData exposure, создающая OData сервис для соответствующей CDS View. Также это могут быть какие-то дополнительные ассоциации (тексты, средства поиска, просто другие ракурсы), описание параметров полнотекстового поиска для различных полей, и т.п.
Выглядит это примерно так:
@AbapCatalog.sqlViewName: 'ZTEST_CPRODAMNT'
@AbapCatalog.compiler.compareFilter: true
@AccessControl.authorizationCheck: #CHECK
@VDM.viewType: #CONSUMPTION
@EndUserText.label: 'Available product amount'
define view Ztest_C_ProductAmount
as select from Ztest_I_ProductAmount
association [*] to Ztest_C_ProductReplenishment as _Replenishment on _Replenishment.Material = $projection.Material
{
key Material,
@EndUserText: {
label: 'Available Amount',
quickInfo: 'Amount available across all shops'
}
AvailableAmount,
_Replenishment,
_Material
}
Примеры двух получившихся Consumption CDS View
На основе данной модели уже можно строить приложение (это может быть сразу фронтенд в лице Fiori, либо какая-то прослойка в виде ABAP кода, либо какое-то еще приложение поверх) или же она может являться моделью для какого-либо API, доступного через gateway (например, для аналитики или статистики). Важно то, что в верхнем уровне иерархии каждый ракурс заточен уже под конкретное его применение, поэтому в нем можно и описать тексты названий полей и заголовков (которые доступны для перевода через SE63), реализовать еще какие-то узкоспециализированные вещи, и так далее. По большому счету создаете сущность, использующую модель данных в CDS - создавайте под нее Consumption View, не стесняясь делать его абсолютно неуниверсальным.
Итого
Конечно, есть случаи, когда модель достаточно проста, и нет необходимости разделять, например, базовый и композиционный уровни, а можно передавать данные уже в таком виде, в котором они есть в таблице (добавив только Consumption View поверх существующей Basic View). Да и ограничения относительно того, где реализовывать какие преобразования, довольно размыта.
Основная идея состоит лишь в следующем:
- basic view - универсальные, независимые, атомарные;
- composite view - специфичные для приложений, но все еще переиспользуемые;
- consumption view - специфичные для одного кейса использования модели, абсолютно непереиспользуемые.
Примерно так выглядит иерархия виртуальной модели данных в CDS. Есть еще другие виды ракурсов, как аналитические, текстовые, бизнес-объекты и т.д. Но это уже совсем другая история…
comments