
Автоматы на службе распределенных транзакций
В этой заметке я расскажу о доменах, построенных на основе конечных автоматов, и распределенных транзакциях, реализованных при помощи таких доменов.
Такой подход я активно использую при разработке сервисов со сложным многоступенчатым поведением, где до сих пор он показал себя довольно неплохо (хотя и не без проблем).
Дисклеймер: данная статья не пытается открыть Америку или сделать прорыв в науке. Это просто набор архитектурных решений, которые я считаю удачными, и которыми я хочу поделиться с сообществом. За подробностями приглашаю под кат, а также буду рад обсудить в комментариях.
UPD: речь не идет про распределенные транзакции БД (вроде X/Open XA), здесь про уровень логики, нежели уровень хранения.
Предыстория
Микросервисная архитектура уже стала де-факто стандартом построения серверных приложений. Этот подход дает нам много хорошего - разделение ответственностей, уменьшение связанности, большая независимость при выборе инструментов и работу в маленьких командах. Однако многие вещи, которые раньше были очень просты, часто настолько, что о них не задумывались, теперь стали болью в заднице архитектора.
Одна из таких вещей - транзакции. Раньше достаточно было просто выполнять целый запрос в рамках одной транзакции БД, чтобы получить гарантии ACID относительно выполняемых операций. БД решали и проблемы конкурентного доступа, и отказоустойчивой записи, и, что главное - атомарности изменений. С переходом к распределенной системе все это стало большой проблемой. Настолько большой, что пришлось создавать подходы, фреймворки и даже специальные БД для ее решения.
Простые транзакции, затрагивающие пару сервисов в рамках одного процесса, можно реализовать с использованием 2-phase commit (2PC). Это в целом подходит, если у вас есть какой-то локальный процесс и какой-то внешний сервис, где нужно сделать изменения в начале локальной обработки, а в конце либо подтвердить, либо откатить.
2-Phase Commit
Пример - выделение IP адреса IPAM сервисом:
- запрос на IPAM сервис на выделение IP адреса (1 фаза)
- IPAM сервис резервирует адрес и возвращает его
- какая-то внутренняя логика, использующая выделенный IP
- запрос на IPAM сервис с подтверждением (2 фаза, commit)
- IPAM снимает резерв и сохраняет IP как выделенный.
При этом если произойдет ошибка, резерв можно отменить через запрос отмены (rollback), либо он сам отменится по таймауту.
Такой подход хорош для простых действий, однако, когда нужно выполнить операцию, затрагивающую сразу много сервисов, этого оказывается недостаточно. К счастью, придуманы и другие подходы, позволяющие это реализовать.
Saga
Один из наиболее популярных подходов - паттерн Saga. Подход очень простой в теории, но достаточно сложный на практике. Во-первых, существуют разные подходы к реализации самой саги (оркестрация, хореография), месте ее реализации (сервис, инициирующий процесс, сервисы участвующие в процессе, отдельный сервис-оркестратор), и у сообщества нет однозначного ответа, когда и как лучше делать, а каких вариантов избегать. Во-вторых, простая идея реализации последовательности выполняемых шагов на разных сервисах значительно усложняется, если брать в расчет такие факторы, как отказоустойчивость выполнения, идемпотентность, сетевые задержки, отказы сервисов и брокеров сообщений, возможные потери данных, различные технологии реализации разных сервисов, различные протоколы коммуникации, синхронные и асинхронные API и прочее. На деле это получается довольно сложный инфраструктурный слой, который, помимо прочего, обычно нужно реализовывать вручную, в то время, когда ACID транзакции уже реализованы силами БД.
В этой статье я расскажу про другой подход к распределенным транзакциям, к которому мы пришли в процессе работы над комплексными распределенными процессами.
Путь к автоматизации
Изначально я не планировал никаких распределенных транзакций. Передо мной стояла задача реализовать конвейерный процесс, где несколько древовидных сущностей создаются или изменяются, и при этом каждое изменение состоит из последовательности шагов. Каждый шаг подразумевает один или несколько вызовов отдельных сервисов.
Также важным требованием была отказоустойчивость процессов. Нельзя было просто прогнать все шаги подряд, а в случае ошибки вернуть ответ об ошибке клиенту. Логика заключалась в создании хитросочененного кластера виртуальных машин с большим количеством нетворкинга, и в случае ошибки нельзя просто бросить все как есть.
Первым вариантом реализации был обычный конечный автомат (FSM) состоящий из последовательности шагов конвейерного процесса. А-ля “создание сети, создание балансировщика, создание ВМ” и т.п. Запросы были разделены на синхронные queries (Read operations) и асинхронные commands (CUD operations) - в парадигме CQRS. Каждому состоянию автомата соответствовали одна или несколько операций перехода в другое состояние, при которых и совершались асинхронные запросы. Ответ на такой запрос триггерил новый переход и т.д.
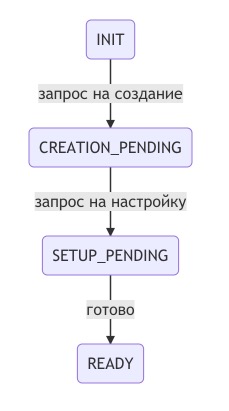
В целом идея была хорошей, но вот реализация никуда не годилась. Реальный процесс довольно сильно отличался от шагов конвейера, описанных автоматом, поэтому требовалось много дополнительных проверок внутри состояния, а сам код получился запутанным, трудно читаемым и абсолютно не покрываемым тестами.
Через какое-то время было решено переписать эту логику, и сделать наконец “нормально”. Это совпало по времени с рефакторингом сервиса в DDD парадигму. В тот момент и родилась идея об автоматизированных доменах, или если проще - доменных автоматах.
Доменный автомат
Термин “автоматизированный домен” я взял у Анатолия Шалыто по аналогии с его автоматизированными классами. Простыми словами это домен в рамках Domain-driven development (DDD), в основе поведения которого лежит конечный автомат.
Самая большая проблема сервиса была в том, что процесс создания не ложился на конвейерную модель, состоящую из последовательности шагов. Дело в том, что сущности, которые нужно было создавать, были не линейными, а древовидными, и у каждого узла был свой процесс создания.
Выглядело это примерно так - корневая сущность проходит какие-то шаги (допустим, кластер ВМ), затем триггерится создание дочерних узлов (группы ВМ, объединенные общими характеристиками), они также проходят какие-то шаги, а затем триггерится создание уже их дочерних узлов (самих физических ВМ), и так далее. Практика показала, что этот процесс очень плохо ложится на конвейер, описанный как последовательность шагов. Как только дочерние сущности начинают создаваться параллельно, конвейер “расслаивается” на набор параллельных шагов, которые сложно описать каким-то статусом. Отсюда и появляются кучи проверок вида “если статус такой, и статусы всех дочерних сущностей такой, и еще такое-то условие, то выполнить действие A”.
Это работало довольно плохо, а для некоторых случаев вообще не работало (как, например, обработка ошибки при создании дочернего узла, который требовал инициировать другую последовательность шагов, например, для удаления сломавшейся сущности).
DDD и FSM
На замену пришел следующий подход: домен (а точнее, доменный агрегат в терминах DDD) представляет собой древовидную структуру из набора доменных моделей. Для простоты возьмем пример с кластером ВМ, где есть корневой домен “кластер”, дочерняя нода “группа ВМ”, и ее дочерняя нода “ВМ”
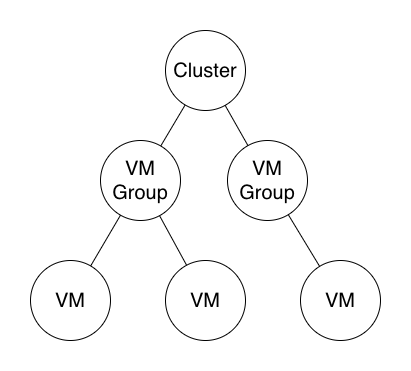
Пример кластера с двумя группами ВМ и тремя ВМ.
При этом каждая модель имеет собственную систему состояний и переходов между ними (конечный автомат). Этот автомат включает только состояния этого узла, но не его родителей, детей или братьев. При этом изменение состояния домена могут триггерить как какие-то действия, так и изменение состояний детей или родителей.
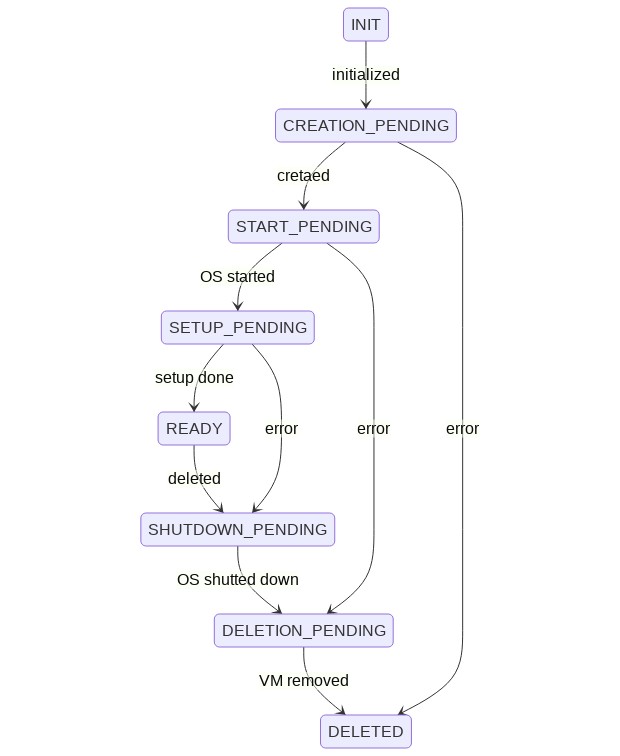
Пример диаграммы состояний ВМ с переходами.
Например, при создании виртуальной машины она в какой-то момент переходит в статус READY. Этот переход триггерит событие VM_READY у родительской сущности - группы ВМ. В этот момент она находится в статусе VM_CREATION_PENDING или вроде того. При событии VM_READY выполняется проверка - а все ли дочерние VM имеют статус READY (помните, что запросы асинхронные, поэтому каждая ВМ проходит свою цепочку статусов параллельно остальным). Когда все дочерние ВМ готовы, сущность “группа ВМ” также меняет статус на READY, и в свою очередь триггерит событие VM_GROUP_READY у родительской сущности - кластера ВМ. Тот проверяет, все ли группы ВМ готовы, ну и так далее. Когда они готовы, кластер также меняет свой статус и запускает следующий шаг обработки. Все изменения статусов обязательно фиксируются в БД.

В итоге получили следующее: доменный агрегат состоит из набора (обычно древовидного) доменных моделей, поведение каждой модели описывает конечный автомат состояний и переходов между ними. При этом изменение состояния каждой доменной сущности может триггерить события как вниз, так и вверх по дереву. Таким образом по ходу какого-то сложного процесса родительская нода может запустить процесс на дочерних нодах и ожидать его исполнения (или говоря языком реализации - быть в статусе *_PENDING). Также она может затриггерить событие для своей родительской ноды, например, если когда та чего-то ожидает, или наоборот, сообщить ей о старте процесса изменения, чтобы она перешла в режим ожидания.
Все это позволяет составным частям доменного агрегата жить своей жизнью - самим управлять своими процессами, отправлять соответствующие запросы, дергать соответствующие сервисы - и при этом оставаться связанными с общей моделью домена. Это очень удобно на практике, потому что логика состояний, проверок и действий при переходах между состояниями остаются инкапсулированными в одном домене, и не интерферируют друг с другом. Разработчик может сконцентрироваться на одной доменной сущности как при дизайне схемы состояний, так при ее практической реализации. Каждая сущность может выполнять свои операции (например, пользователь может захотеть выключить ВМ, для этого обработка будет реализована именно в домене ВМ), а для синхронизации с остальным доменным агрегатом достаточно “уведомить” своих родителей или детей посредством соответствующего события.
Реализация автомата
Кроме того, сам автомат очень просто реализуется в любом языке программирования. Есть два основных подхода - статическая реализация через switch и динамическая через таблицу состояний и переходов. Я предпочитаю первый вариант, так как код становится значительно более читаемым, а логика более понятной и очевидной. Плюс, если вы используете компилируемый язык, это дает дополнительные проверки при компиляции.
Мы используем Go, где автомат выглядит примерно так:
// State тип может быть любой, но удобно использовать строки, которые сохраняются в БД,
// чтобы было проще ориентироваться в состояниях доменов.
// Можно использовать и int или любой другой тип,
// который подойдет для описания состояния.
type State string
const (
Init State = "INIT"
CreationPending State = "CREATION_PENDING"
StartPending State = "START_PENDING"
SetupPending State = "SETUP_PENDING"
Ready State = "READY"
ShutdownPending State = "SHUTDOWN_PENDING"
DeletionPending State = "DELETION_PENDING"
Deleted State = "DELETED"
)
// Event эти значения обычно нигде не хранятся,
// поэтому можно использовать просто enum или его аналог (в Go это const + iota)
type Event int
const (
Initialized Event = iota + 1
Created
Started
SetUp
DeletedManually
ShutDown
Removed
ErrorOccured
)
// VM is a Virtual Machine domain model
type VM struct {
s State
}
func (vm *VM) handleEvent(e Event) error {
switch vm.s {
case Init:
switch e {
case Initialized:
err := createVM()
if err != nil {
return err
}
vm.s = CreationPending
}
case CreationPending:
switch e {
case Created:
err := startVM()
if err != nil {
return err
}
vm.s = StartPending
case ErrorOccured:
err := deleteVM()
if err != nil {
return err
}
vm.s = DeletionPending
}
case StartPending:
//...
}
return nil
}
“А при чем здесь распределенные транзакции?” - спросит внимательный читатель. Чтож, когда идея подхода понятна, пришло время поговорить и о них.
Распределенные транзакции с использованием доменных автоматов
Если внимательно посмотреть на паттерн Saga, будет видно, что в его основе тоже лежит конечный автомат. Обычно этот автомат реализован либо в одном месте (в случае оркеструемой саги), либо разбросан по системе (в случае хореографической саги). Однако в любом случае это последовательность действий, выполняемых набором синхронных или асинхронных вызовов (или событий), которая определяется набором статусов. Эти статусы описывают состояние саги в момент времени. Это не обязательно именно явные статусы у каждой сущности, но это в любом случае какое-то “состояние”, в котором находится сага, и это состояние хранится персистентно (в хранилище данных) в виде одной или нескольких сущностей.
Внимательный читатель заметит, что концепция доменных автоматов тоже основана на конечных автоматах и на персистентном хранении состояния. В чем же разница?
Разница, действительно, на первый взгляд нечеткая. Но она есть, причем, довольно значительная. И чтобы понять ее, нужно взглянуть на процесс изменений, которым и управляет тот или иной подход.
Ориентация на процесс и ориентация на данные (домены)
Любые действия, происходящие в системе (в нашем случае распределенной), объединяют два направления - процесс изменений и изменяемые данные (а на более глобальном уровне кросс-доменный процесс и изменяемые домены). Так, одна транзакция БД объединяет логический набор операций, выполняемых над данными (исторически это была одна банковская транзакция, отсюда и название), и сами модели, данные которых претерпели изменения.
Графически это можно изобразить так:

Здесь по одной оси идет процесс (P), который можно описать как “нужно создать кластер, затем создать внутри него сеть, затем для каждой группы ВМ создать балансировщик нагрузки, а затем запустить все ВМ из образов”.
По другой оси идут изменения в данных (D), например “сущность кластер меняет получает параметры созданной сети и меняет статус, затем ждет готовности групп ВМ и меняет статус. Группа ВМ получает параметры созданного балансировщика нагрузки и меняет статус, затем ждет готовности ВМ и меняет статус. ВМ получает параметры созданной на сервере ВМ и меняет статус. Затем она ожидает запуска созданной ВМ и меняет статус”.
Это довольно грубое упрощение, но суть должно показывать. Теперь давайте разберемся с подходами.
Saga - транзакция, ориентированная на процесс
Или process-oriented transaction. Она описывает, в первую очередь, какой процесс происходит, из каких шагов он состоит, в какой последовательности они выполняются на каких сервисах. При этом, если одни и те же сущности участвуют в разных процессах, это будут отдельные и никак не связанные “описания”. Например, две саги, объединяющие два различных бизнес-процесса, могут иметь одни и те же шаги по работе с одним сервисом, при этом сам сервис не будет в курсе, что от его работы зависят какие-то определенные процессы.
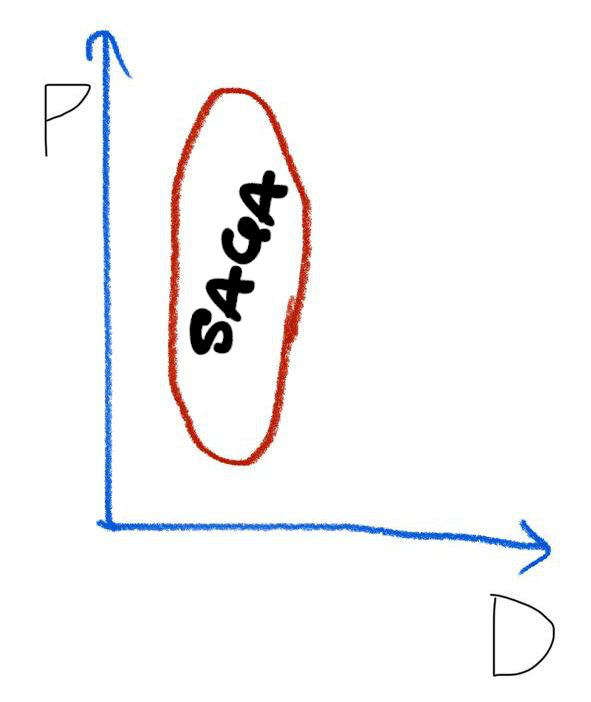
Это хорошо с точки зрения разделения ответственностей, но часто приводят к проблеме “распределенного незнания” - когда не понятно, как именно выполняется данный процесс, или в какие процессы вплетен существующий API сервиса.
Саги хорошо справляются с задачей описания шагов процесса языком, близким к доменному, но при этом теряют обратную связь: взяв за начальную точку конкретный сервис, тяжело отследить, где и как он используется (с целью внесения обратно несовместимых изменений, например).
Именно эту проблему (а еще несколько других) решает подход доменных автоматов.
Доменные автоматы - транзакция, ориентированная на домен
Или domain-oriented transaction. В отличие от Saga, в рамках этого подхода последовательность действий зависит от текущего состояния домена (данных, доменного агрегата - you name it), и описывается именно им.
Ключевое различие состоит в том, что в случае Saga описание шагов бизнес-процесса локализовано, но при этом упускается обратная связь с изменяемыми доменами (или просто данными) - нельзя легко проследить, что приводит к конкретным действиям над доменом без наличия дополнительной документации (а где есть дополнительная документация вне кода, там есть устаревшая документация).
Доменные автоматы, наоборот, локализуют описание изменений домена в рамках самого домена, при этом процесс, в рамках которого происходят изменения, вторичен.
Такой подход очень хорошо ложится на DDD, потому что можно переложить информацию, полученную от бизнеса, на соответствующий домен, и реальные состояния и переходы будут соответствовать состояниям и переходам в FSM соответствующего домена. Более того, все процессы, описываемые этими автоматами, будут локализованными в рамках связанного контекта (Bounded Context) данного домена или группы доменов.
Но даже если вы не используете DDD, этот подход поможет сосредоточить знания об изменениях над данными вместе с этими данными. Таким образом, вы больше не привязаны к описаниям шагов бизнес-процессов - ваш сервис содержит понимание о том, в каких состояниях могут находится его данные, и что делать, если в каждом из этих состояний с данными происходят какие-то события.
Идеологически это чем-то похоже на хореографическую сагу, потому что у вас больше нет единой точки управления процессом - вы запускаете процесс в одном сервисе, а дальше он сам делает все нужное, пока не дойдет до какого-то конечного состояния. Это не обязательно должно быть изначально ожидаемое состояние - в случае ошибки где-то посередине процесса вам больше не нужно контролировать запуск компенсирующих транзакций - конечный автомат описывает, что делать, если ошибка приключится на каждом из состояний каждой из задействованных сущностей.
Помните, что мы создаем ВМ параллельно? Это многоступенчатый процесс, который состоит из нескольких последовательных шагов. Случай, когда при создании одной из них произошла ошибка, довольно сложно описать в рамках Saga. Что делать? Откатывать все изменения? Делать retry? Как определить конкретное состояние кластера? Он сфейлился или нет? Конечно, всю эту логику многослойных проверок можно реализовать, но читать и поддерживать такой код будет очень болезненно.
На основе доменных автоматов это решается очень просто. Конкретная доменная модель отвечает за конкретную сущность и все процессы, связанные с ней. В случае с ошибкой при создании ВМ, обработка довольно проста:
- домен ВМ проверяет, в каком состоянии он находится сейчас, и в зависимости от этого переходит в другое состояние, сопровождающееся новыми вызовами. Например, если ВМ в статусе ожидания старта ВМ (
VM_START_PENDING), то при ошибке нужно сначала удалить созданную ВМ, чтобы освободить ресурсы. ВМ переходит в статусVM_DELETION_PENDINGи отправляет гипервизору запрос на удаление инстанции. Если же ошибка произошла на шаг раньше, когда статус был “ожидание создания ВМ” (VM_CREATION_PENDING), то удалять ничего не нужно (ничего не создано), и вместо перехода в статусVM_START_PENDINGможно сразу переходить в статусDELETED. - домен ВМ уведомляет родительскую сущность о том, что создание ВМ не удалось, и делегирует ей принятие дальнейших решений. В свою очередь родитель в виде домена “группа ВМ” решает, что делать - попробовать создать новую ВМ (например, на другом физическом сервере), или остановить и удалить остальные ВМ, и сообщить об ошибке “выше” - родительскому домену “кластер ВМ”.
В этом случае доменный агрегат сам в состоянии справиться с любой ошибкой, т.к. у него есть вся необходимая для этого логика, а также в рамках домена (как в программе, так и в реальном мире) есть нужные знания для того, чтобы принимать решения (например, что делать в случае ошибки при создании ВМ).
Плюсы
Я буду сравнивать этот подход в основном с паттерном Saga, так как оба применимы для сходных задач.
Разделение ответственностей
Одно из преимуществ состоит в том, что ответственность за логику изменения состояния и сопряженных с этим действий ложится непосредственно на тот домен/класс/сущность, к которому(ой) эта логика и относится. Домен инкапсулирует не только сами действия при разных запросах и событиях, но и контроль за соблюдением правильной последовательности действий и их консистентности.
В отличие от Saga, где процесс описывается с точки зрения последовательности действий, без углубления в особенности реализации на каждом шаге (что в перспективе приводит к появлению “костылей”), доменный автомат учитывает все особенности доменного агрегата, включая “особое” поведение и всякие трюки и хаки, которые могут потребоваться для оптимизации или для сокращения сроков разработки (я этого не говорил).
Гранулярность моделей
Так как модель домена может быть сложной, наивно пытаться впихнуть все в один автомат. Нормальным вариантом будет реализовать отдельный автомат для каждой сущности в рамках домена (узла в дереве модели), а также в рамках нескольких доменов, которые реализует ваше приложение.
В этом случае возникает вопрос - как разные автоматы должны общаться между собой?
Я реализую это следующим образом. Любое действие над автоматизированным доменом происходит через событие. Происходит такая проверка: состояние -> событие -> условия. Например, при получении события VM_GROUP_READY домен “кластер ВМ” проверяет сначала свое состояние, затем для каждого состояния выполняется обработка события, а для конкретного события выполняется проверка условий, при которых можно осуществить переход к следующему статусу. Так, если “кластер ВМ” находится в состоянии VM_GROUP_CREATION_PENDING, то для события VM_GROUP_READY он выполнит проверку, все ли группы ВМ находятся в статусе READY, и если да - выполнит переход к собственному статусу READY с выполнением сопутствующих действий (например, отправит на фронтенд сообщение о готовности кластера).

Инкапсуляция сложности
Доменные автоматы позволяют убрать сложную доменную логику вовнутрь, предоставив клиенту (будь то API сервиса или другой домен в этом же сервисе) упрощенный интерфейс, в котором нет лишних деталей. Например, для примера с кластером это будет интерфейс с методами
- создать кластер
- удалить кластер
- добавить ВМ
- удалить ВМ
- изменить параметры группы ВМ
Эти методы могут вызывать другие доменные автоматы, или та же Saga (если она у вас уже используется), либо напрямую клиент.
Хорошо подходит для DDD
Реализация описанного подхода хорошо ложится на архитектурные подходы в рамках DDD. В моем случае я добавляю поле State в каждую доменную модель, а сервис домена реализует логику событий, состояний и переходов конкретного домена. Сервис доменного агрегата либо доменный сервис сложного домена (например, древовидная структура с дочерними сущностями) реализует общение между разными сущностями в рамках домена (отношения родитель-потомок с соответствующим обменом событиями или прямыми вызовами методов). Сервис слоя приложения оборачивает автоматизированные домены в общую для приложения бизнес-логику, проверки, а также представляет некий упрощённый фасад над ними. Также на этом уровне реализуется взаимодействие между разными доменными агрегатами, если их в сервисе больше одного.
Читаемый и простой код
С этим пунктом можно поспорить - получающийся в итоге код все равно довольно сложный. Так, сам метод, содержащий FSM (при условии, что логика переходов вынесена в отдельные методы) может запросто занимать под 300 строк для автомата из дюжины состояний (по крайней мере в Go).
Однако, если сравнивать с тем же паттерном Saga, то получаемый код действительно намного лучше читается, а главное - он значительно лучше структурирован - вся доменная логика сосредоточена в домене, описание состояний и переходов лежит в одном месте, логика проверок при переходах - рядом, логика действий при выполнении проверок - тоже рядом. Конечно, хорошая документация никогда не помешает, и мне на помощь приходит Godoc и диаграммы состояний в Readme (благо, Gitlab умеет рендерить mermaid диаграммы из коробки).
К сожалению, если процесс действительно очень сложный, то и соответствующая диаграмма состояний, и реализующий ее код будут очень большими и уже не так легко читаемыми - но это все еще лучший вариант из того, что я знаю. Сложные программы писать и читать сложно.
Минусы
Как и у любой архитектурной идеи, у данного подхода есть как плюсы, так и минусы, а также довольно жестко ограниченная область применения.
Подходит не для всего
Описание состояний домена через конечный автомат - довольно комплексная и многословная вещь. Далеко не для каждой задачи это нужно. Если ваш сервис реализует простые CRUD операции, пихать туда автомат будет неоправданным переусложнением.
Подходит не для всех
Конечные автоматы - тема, которую проходят в рамках классического CS образования, однако на практике это встречается довольно редко. Вероятно, вам придется объяснять своим коллегам, что такое FSM и зачем они нужны.
Со временем автомат может сильно разрастаться
Представьте себе сущность, у которой есть 8 состояний - от момента создания до окончательного удаления, и что-то еще при изменении. На каждое состояние прибавьте по два-три события, обработка которых предусмотрена приложением. Туда еще часто добавляются какие-то проверки/валидации, особенно если у сущности есть дочерние сущности со своими автоматами. Ну и вызов логики, которая отрабатывает при переходе в другое состояние не забудьте добавить.
Итого, получается худо-бедно 8*3*3=72 строки + обработка ошибок, итого за сотню. Если это ЯП с невыразительным синтаксисом (как Go), то смело накидывайте еще столько же. При увеличении количества состояний длина метода с автоматом растет квазиквадратично. А так как сам автомат представляет собой большой switch оператор, в какой-то момент вы можете оказаться с методом в 500 строк, из которого исполняется 10.
Можно пойти другим путем, и не писать switch на все состояния домена в одном методе, а разбить это таким образом, что каждому событию будет соответствовать отдельный метод, а внутри будет switch только с теми состояниями, которые умеют это событие обрабатывать. Мне больше нравится первый подход, потому что весь FSM описан в одном месте, но второй тоже неплох и лучше в плане читаемости.
Низкая связанность в рамках глобального процесса
Низкая связанность сервисов хороша для разработки и поддержки, но усложняет восприятие всего приложения и кросс-сервисных процессов в нем. Так как, в отличие от саг, доменные автоматы локализованы внутри одного домена или доменного агрегата, для разработчика может быть затруднительным оценить весь процесс целиком, найти где он начинается и заканчивается.
Эта проблема - следствие того, что доменный автомат является domain-oriented транзакцией, в отличие от саги. Поэтому информацию о роли домена в глобальном бизнес-процессе приходится добавлять дополнительно (в виде текстовой документации или диаграмм). Ниже я расскажу, как я решаю эту проблему.
Как реализовать распределенную транзакцию, используя доменные автоматы
Итак, мы обсудили, что же такое доменный автомат, и чем он отличается, а чем схож с паттерном Saga. Пора разобраться, как же реализовать большую и сложную распределенную транзакцию, используя этот подход.
Как вы помните, автоматы помогают сделать домен самостоятельным элементом, который умеет контролировать свое создание, удаление и различные операции. При этом он знает, какие запросы нужно отправить при каждом переходе от одного статуса к другому.
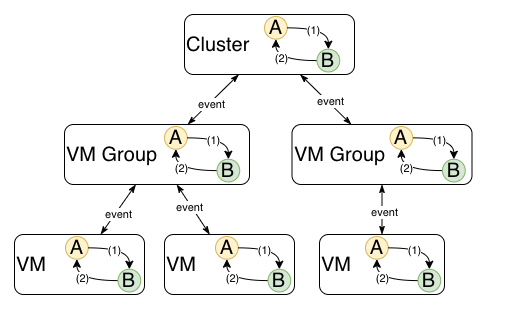
Доменный агрегат, представляющий собой дерево из простых доменов. Либо просто древовидный домен. Каждый домен содержит автомат, каждая сущность домена характеризуется состоянием.
Таким образом, распределенная транзакция, реализованная на основе доменных автоматов, совмещает в себе черты оркеструемой и хореографической саги, и вот как это получается.
Оркестрация
Как и в случае с оркеструемой сагой, автоматизированный домен знает, что конкретно нужно сделать, чтобы осуществить переход от состояния А к состоянию Б. Например, это может быть создание сущности С, за которую отвечает другой сервис. В этом случае домен будет контролировать создание сущности С, то есть выступать для нее оркестратором. Также домен знает, что нужно предпринять в случае ошибки в процессе создания С - будь то какие-то еще действия, или просто переход в другое состояние.
Хореография
Несмотря на то, что домен знает, что делать при переходе между состояниями, он абсолютно ничего не знает о том, откуда в него прилетают события (или команды), инициирующие эти переходы. И этим он похож на хореографическую сагу - каждый домен выполняет какую-то свою часть процесса, не подозревая, откуда и как он был вызван, централизованный узел при этом не требуется.
Комбинация
В итоге получается, что доменный автомат работает в одну сторону (исходящих вызовов) как оркестрируемая транзакция и в другую (входящих вызовов) - как хореографическая. Таким образом распределенная транзакция состоит из цепочки или дерева доменных автоматов, где конкретный домен является оркестратором для своих дочерних доменов в ходе транзакции, и одновременно является участником хореографии для всех родительских автоматов кроме прямого родителя (тот явно управляет действиями домена, являясь его оркестратором).
На картинке изображен пример простой транзакции, состоящий из трех доменов (доменных агрегатов), где домен A напрямую управляет процессом на домене B (оркеструет его), а домен B управляет доменом C. При этом домен А не имеет прямого управления над доменом C, таким образом с точки зрения домена A процесс, происходящий в домене C является хореографическим. Это звучит несколько заумно, но если упростить, то получится так: конкретный домен управляет только ближайшими к нему доменами по ходу транзакции.
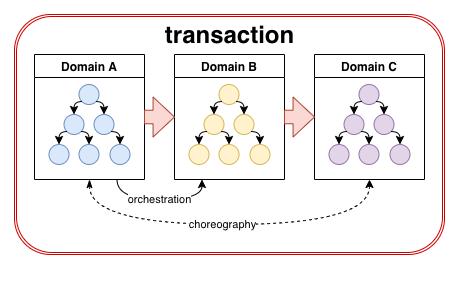
Здесь цепочка вызова транзакции направлена слева-направо (домен A вызывается в начале транзакции, затем он инициитует измененя в домене B, а тот, в свою очередь, вызывает домен C.
На практике же это значит, что первый в цепочке (дереве) домен управляет началом и окончанием процесса, а также его ключевыми этапами. Так, в транзакции, описывающий создание заказа на доставку еды из ресторана, первый домен будет инициировать создание заказа в других сервисах по цепочке, а также контролировать завершение процесса создания заказа и обработку возможных ошибок.
При этом сервис может управлять конкретной последовательностью вызова других сервисов (древовидная транзакция), а может делегировать ее управление следующим доменам (цепная транзакция).
Древовидная транзакция
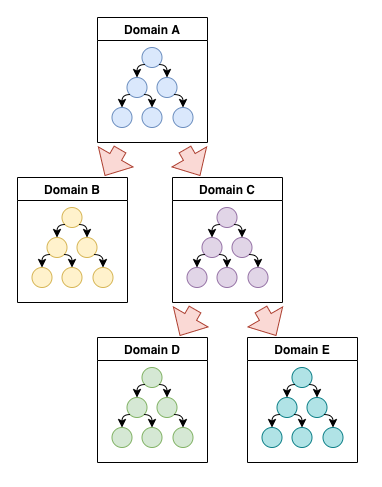
В первом случае основная логика будет сосредоточена именно в первом сервисе, и каждый домен в дереве вызова будет содержать тем меньший кусок логики, чем дальше он от корня.
Цепная транзакция

Во втором случае логика распределяется более равномерно. При этом каждый последующий домен осуществляет контроль за последующим процессом, то есть роль оркестратора передается по цепочке слева направо.
Документация
Как бы то ни было, задача описания всей транзакции в одном месте невыполнима при помощи доменных автоматов - как бы то ни было, каждый домен будет держать собственную логику при себе.
В этом случае не остается другого выбора, кроме как обложить процесс документацией, выходящей за рамки одного сервиса.
Я, как разработчик, с сомнением отношусь к технической документации, которая живет где-то отдельно от кода. По личному опыту такая документация почти всегда устаревает и почти никогда не обновляется. Поэтому я веду документацию проектов рядом с кодом - в Readme (который может быть не только в корне репо, но и в каждом домене, например).
Если говорить про описание распределенных транзакций, самое место для такого описания - в сервисе, который транзакцию инициирует и (в рамках подхода) заканчивает.
При этом не обязательно это должен быть какой-то один сервис для всех транзакций - нормальный случай, когда в одном процессе сервис А начинает транзакцию, которая проходится по доменам сервисов B и C, а в другом случае сервис B запускает другую транзакцию, которая передает управление сервисам A и D, и так далее.
Для меня лучше всего работает формат краткого описания, снабженного подробными диаграммами, но для вас может работать что-то другое. В описании транзакции обычно не имеет смысл сильно углубляться в реализацию, так как она принадлежит доменам и может со временем меняться независимо от сервиса, где документация ведется. Вместо этого будет достаточно описать базовые шаги и сервисы, на которых они выполняются, также возможные логические ветвления процесса.
Обобщение
Как это решило мою проблему: мой процесс состоит из запуска довольно сложного кластера, который работает поверх вендорской VM платформы. В основе процесса лежит несколько доменных агрегатов, каждый из которых состоит из дерева доменных моделей (какие-то побольше, другие поменьше). Основной сервис оркестрирует процесс, инициируя запросы к другим сервисам через асинхронные запросы. Еще полдюжины сервисов обрабатывают эти запросы, инициируя собственные процессы и продолжая цепочку.
В случае инфраструктурных проблем (сеть упала, под перезапустился, бд прилегла) выполняются ретраи для синхронных запросов / повторное чтение из кафки для асинхронных.
В случае логических проблем автоматы позволяют для каждой доменной модели и каждого его состояния обработать ошибку соответствующим образом. Например, если ВМ упала на моменте создания (например, на физическом сервере закончилось место), достаточно перейти к состоянию DELETED и передать событие об ошибке родительской сущности. А если ВМ упала в процессе конфига посте старта ОС, то при ошибке нужно сначала выключить ОС, а затем удалить ВМ, только после этого перевести в состояние DELETED:
Таким образом, каждая из сущностей сама умеет выполнять компенсирующие действия. Не требуется какой-то “транзакции”, которая будет это контролировать - поведение системы привязано к ее актуальному состоянию, поэтому исключены проблемы с изоляцией.
Заключение
Данный подход не претендует на какой-то прорыв в теме распределенных транзакций, либо на пример архитектурного стандарта. Я также допускаю, что все уже придумано до меня, и я просто не знаю, как правильно это загуглить.
Однако подход с доменными автоматами и транзакциями на их основе оказался весьма полезным для меня и довольно сложной и запутанной логики, с которой мне приходится иметь дело. Также я вижу его как оправданную, хоть и сложную альтернативу паттерну Saga, который имеет весьма противоречивые отзывы в сообществе разработчиков.
Буду весьма признателен за любую критику, советы и отсылки к интересным материалам. Приглашаю в комментарии обсудить сам подход и его узкие места, а также варианты улучшения и упрощения.
P.S.: а вот отличная статья про Анатолия Шалыто. Я сам не знал про него, когда читал его книгу, а потом встретил такую историю, которая мне очень понравилась. Просто делюсь.
comments